




新智元报道现货白银杠杆
编辑:编辑部 JHZ
【新智元导读】GPT-4.5上线一天,已经引起了集体群嘲:这个模型彻头彻尾失败了,OpenAI已经陷入严重困境,失去护城河!有人算出,GPT-4.5比DeepSeek V3贵了500倍,性能却更差。有的权威AI预测者看完GPT-4.5,气得直接把AGI预测时间推后了……当然了,OpenAI并不这么认为。
自从OpenAI发布GPT-4.5之后,Ilya这张图又开始火了。
GPT-4.5令人失望的表现,再次印证了Ilya这句话的含金量:预训练已经达到极限,推理Scaling才是未来有希望的范式。
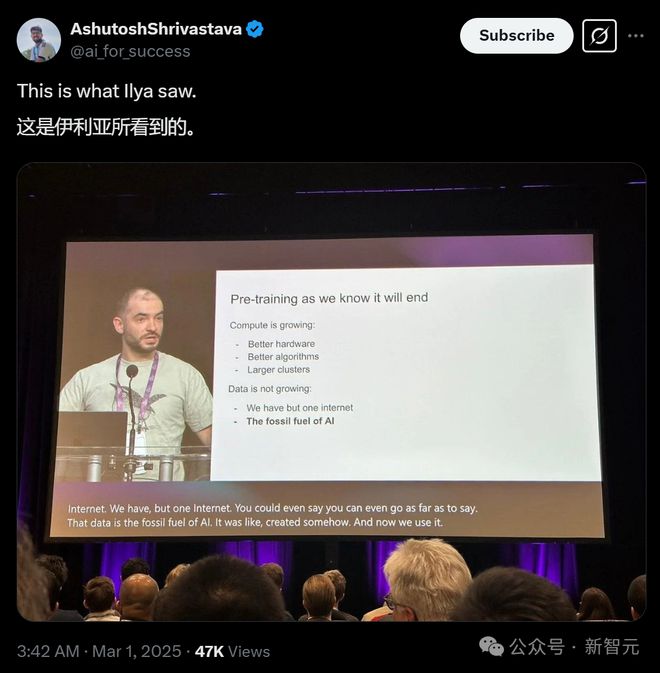
GPT-4.5在基准测试上并没有提升,推理没有增强,只是变成了一个更易于合作、更有创造性、幻觉更少的模型。
GPT-4.5的「失败」更加证明,Ilya是对的。
现在,各方评测都已经出炉,结果显示,OpenAI实在是太打脸了。
从ARC-AGC的评估上来看,GPT-4.5几乎跟GPT-4o处于同一水平,智能上似乎没有任何提升。
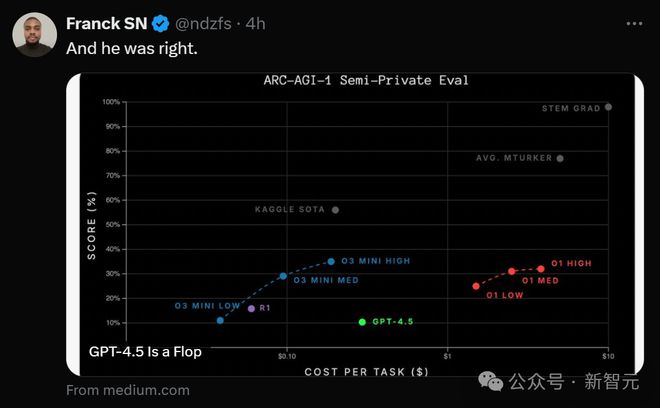
纽约大学教授马库斯直接发长文痛批:GPT-4.5就是个空心汉堡。

一位AI初创CEO更是直言:在自己心目中最实用评估基准Aider Polyglot上,OpenAI的「镇国之宝」GPT-4.5,比DeepSeek-V3贵了500倍,但表现反而更差。
如果这个结果准确,那OpenAI将陷入严重困境,甚至是彻底失去护城河!

与此同时,国内这边DeepSeek连续6天给人们带来了开源暴击,R1模型直接减价75%。
总之,在DeepSeek、xAI Grok 3、Anthropic首个混合模型Cluade 3.7 Sonnet等的前后夹击之下,OpenAI这位昔日明星,如今显然已风光不再。

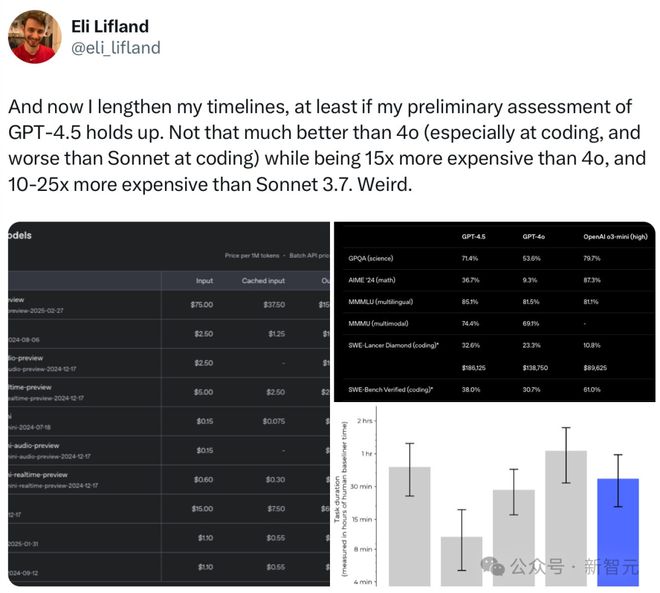
「GPT-4.5真这么差?我不会看错了吧」
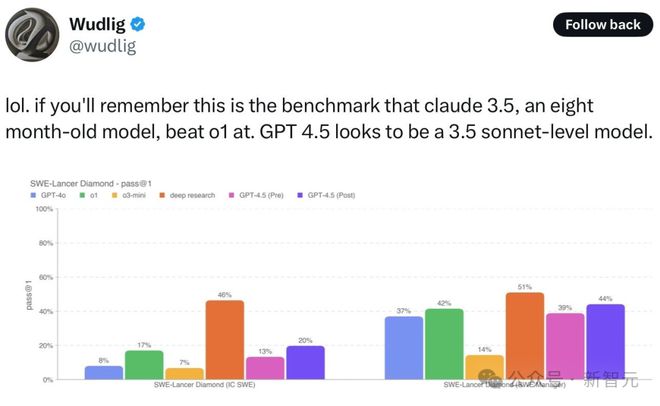
正如上文所提,刚刚那位AI初创CEO在看到下面这张图表后,感觉实在难以置信,因为GPT-4.5 Preview的表现,直接全班垫底。

为此,他还求证了表格制作者,对方表示自己仔细检查了性能数据,进行了多次运行,能保证每个结果都是对的。
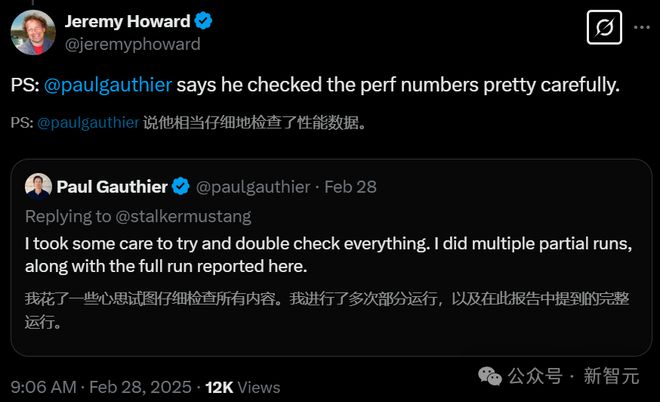
GPT-4.5比GPT-4基础模型多出了10倍的预训练计算量,但却什么都不擅长,这合理吗?
有人猜测说,GPT-4.5可能并没有经过太多的监督微调,因为OpenAI本来是打算将其作为未来模型(如GPT-5)的基础模型或教师模型,用于进一步通过强化学习进行微调的。
可能是这个原因,导致它在代码的指令遵循上不算特别强。

或者,问题可能出在了数据混合上,因为OpenAI这次采用了一种全新的训练机制,所以可能有某种「成长痛」。
不过令人心凉的是:OpenAI内部许多能做到这件事的人,如今已经走了。
有人直接开麦表示:「如果DeepSeek能有OpenAI的资金量,那我们就完蛋了」。
还有人调侃道,这可能就是所谓的「用智商换情商」吧。
不管怎么说,在大家眼中,OpenAI的先发优势已经不复存在了。
左右滑动查看
马库斯:OpenAI彻底失去护城河
马库斯转发了这个结果惊人的研究后表示,不管OpenAI在两年前有什么优势,如今他们已经彻底失去了护城河。
虽然他们现在仍拥有响亮的名字、大量数据和众多用户,但相对竞争对手并未拥有任何决定性的优势。
Scaling并没有让他们走到AGI的终点。GPT-4.5非常昂贵,GPT-5也失败了。
所有人都开始疑问:OpenAI能拿出的,就只有这么多了?
现在,DeepSeek已经引发了一场价格战,削减了大模型的潜在利润。而且,目前还没有任何杀手级应用出现。
在每一次模型的响应中,OpenAI都在亏损。公司的烧钱速度如此之快,但资金链却有限,连微软也不再完全支持他们了。

如果不能快速转型为非营利组织,一大笔投资就会变成债务。
而且,Ilya、Murati、Schulman……许多顶尖人物已经离开。
如果孙正义改变主意,OpenAI就会立刻面临严重的现金问题(马斯克有一句话说对了,星际之门的很大一部分资金,他们并没有拿到手)。
总之,在推出ChatGPT上,奥特曼确实是那个正确的CEO,但他并没有足够的技术远见,带领OpenAI迈向下一个阶段。
在这篇《GPT-4.5是个空心汉堡》中,马库斯也再次强调:Scaling已经撞墙了。
在GPT-4.5发布前,他就预测将是一场空欢喜,而LLM的纯粹Scaling(无论是增加数据量还是计算)已经撞墙。
在某些方面,GPT-4.5还不如Claude上一个版本的模型。
甚至第一次出现了这种情况:颇受尊敬的AI预测师感到极度失望,以至于推迟了自己对于AGI何时到来的预测时间。
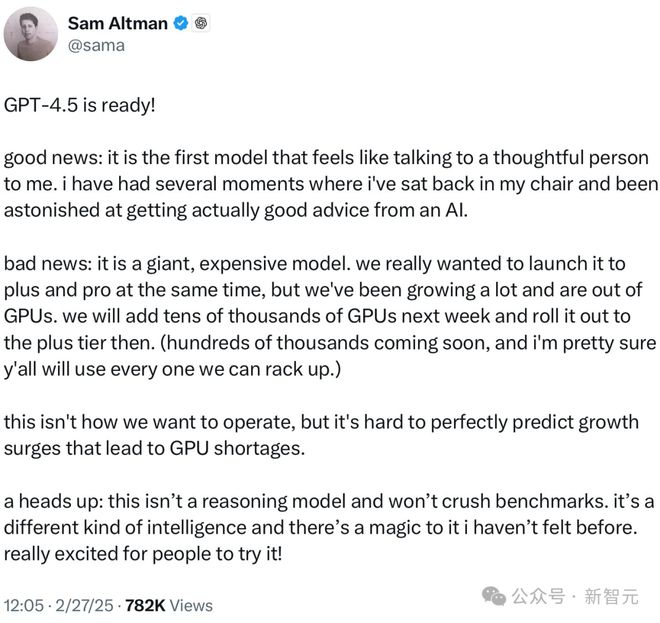
而奥特曼在产品发布上的异常冷静,就更耐人寻味了。
他没有像往常那样大肆宣传AGI,而是承认了大规模模型的成本,却对AGI完全避而不提。
总之,马库斯表示,自己在2024年的预测依然强劲——
耗费五千亿美元后,依然没人找到可行的商业模式,除了英伟达和一些咨询公司之外,没人获得了可观的利益。
没有GPT-5,没有护城河。
「Scaling是一个假设,我们投入了相当于阿波罗计划两倍的资金,但至今并未取得太多实质性成果。」
GPT-4.5:不求最好,但求最贵
总之,从输入价格来看,GPT-4.5可谓是贵到离谱:
但正如前文所说,作为「最贵」模型的GPT-4.5,在表现上却不是「最好」的。
跑分一个第1都没有
由知名华裔亿万富翁Alexandr Wang创办的Scale AI,定期会更新一套基于私有数据集的LLM排行榜SEAL,目前首页上共有15个。
然而,在这波最新的排名中,GPT-4.5 Preview竟然没有一项取得第一!
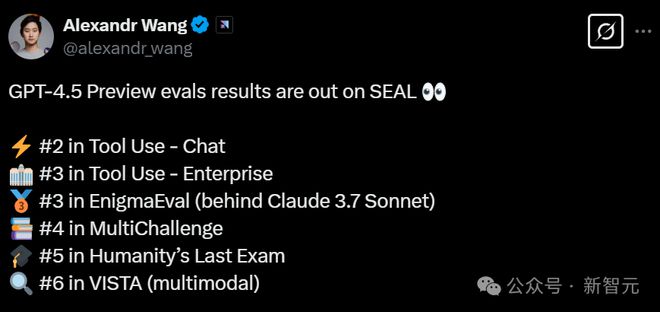
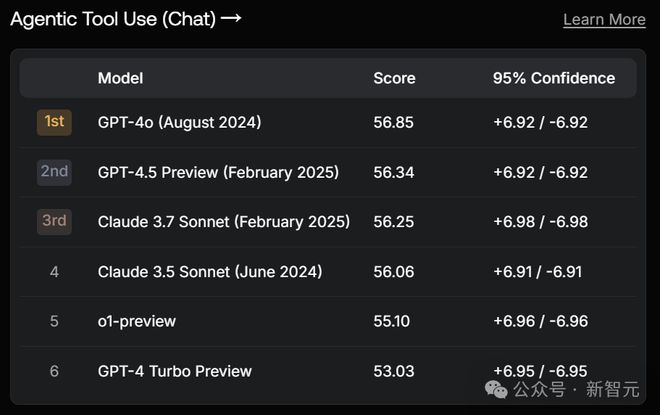
全场最佳成绩,是智能工具使用(Chat)项目的亚军——略强于Claude 3.7 Sonnet,但次于上一代GPT-4o。
接下来,GPT-4.5在EnginmaEval,Agentic Tool Use(Enterprise)两个项目上,取得第3。
其中,前者需要创造性地解决问题和综合不同领域信息的能力;后者评估模型工具使用的熟练程度,特点是需要将多个工具组合在一起。
分别输给了自家的o1/o1-preview和竞争对手最新的Claude 3.7 Sonnet(Thingking)。

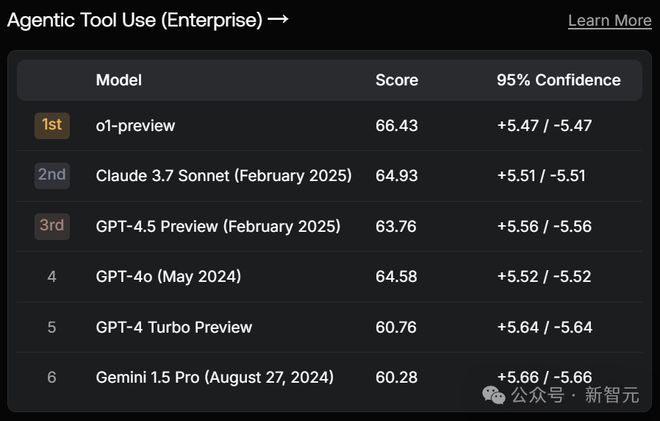
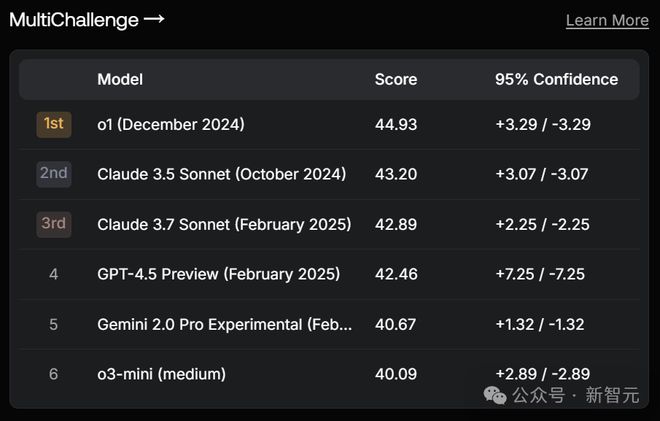
在MultiChallenge中,排名第4,输给了o1、Claude 3.5 Sonnet和3.7 Sonnet。
榜单MultiChallenge用于评估LLM与人类用户进行多轮对话的能力,考察LLM的指令保留、用户信息推理记忆、可靠版本编辑和自我一致性等4方面上的指令遵循、上下文分配和在上下文中推理的能力。
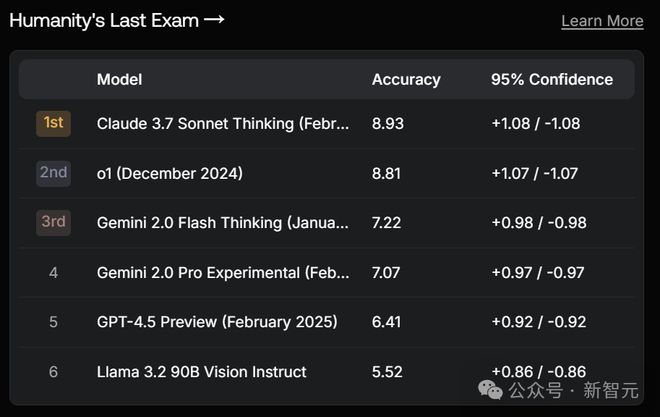
在「人类最后一次考试」中,排在第5。
这次,它不仅输给了Anthropic的Claude,就连Gemini也骑在了它的头上。甚至,还是Flash版本。
顾名思义,这里测试的是LLM推理深度(例如,世界级数学问题)及其学科领域的知识广度,提供对模型能力的精确测量。目前,还没有模型的真确率能达到10%。
千万不要用来编程
根据Aider的LLM编程排行榜,OpenAI旗下AI模型性价比都不高,而GPT-4.5是性价比最差的。
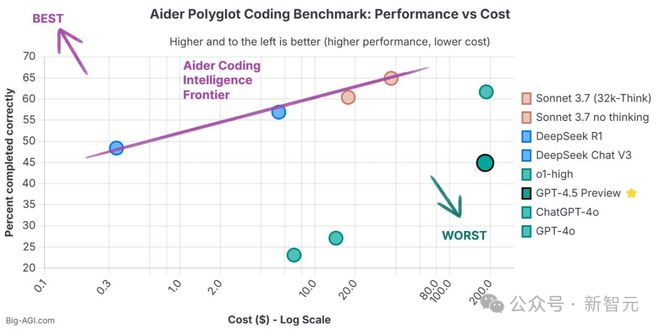
创立AI公司的Enrico则表示,除非你愿意做「冤大头」或「人傻钱多」,否则在编程中不要使用GPT-4.5。
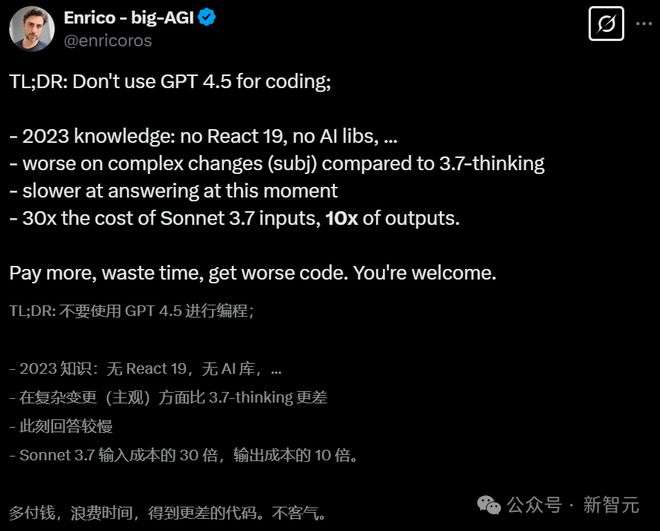
但其实,这些现象或许也在情理之中,毕竟按照OpenAI的说法,这次既不看智商也不看性能,而是强调「啥都懂」和「情商高」。
OpenAI首席研究官:我们还能Scaling!
虽然外面的争论异常激烈,但在OpenAI首席研究官Mark Chen看来,GPT-4.5的发布正是说明模型在规模上的Scaling还没达到极限。
同时,对OpenAI而言,GPT-4.5也是对那些质疑「Scaling模型规模可以继续取得进展」的回应:
「GPT-4.5实实在在地证明了我们可以继续沿用Scaling Law,并且代表着我们已经迈入了下一个数量级的发展阶段。」

预训练和推理,两条路并行
如今,OpenAI正沿着两个不同的维度进行Scaling。
GPT-4.5是团队在无监督学习上最新的扩展实验,与此同时,团队也在推进推理能力的进展。
这两种方法,是相辅相成的:「为了构建推理能力,你首先需要知识基础。模型不能盲目地从零开始学习推理。」
相比起推理模型,拥有更多世界知识的GPT-4.5,在「智能」的体现方式上完全不同。
使用规模更大的语言模型时,虽然需要更多时间处理和思考用户提出的问题,但它依然能够提供及时的反馈。这一点与GPT-4的体验非常相似。而当使用像o1这样的推理模型时,它需要先思考几分钟甚至几分钟,才会作答。
对于不同的场景,你可以选择一个能够立即回应、不需要长时间思考但能给出更优质答案的语言模型;或者选择一个需要一段时间思考后才能给出答案的推理模型。
根据OpenAI的说法,在创意写作等领域,更大规模的传统语言模型,在表现上会显著优于推理模型。
此外,相比于上一代GPT-4o,用户在60%的日常使用场景中也更喜欢GPT-4.5;对于生产力和知识工作,这一比例更是上升到了近70%。
GPT-4.5符合预期,没有特别困难
Mark Chen表示,OpenAI在研究方法上非常严谨,会基于所有之前训练的LLM创建预测,以确定预期的性能表现。
对于GPT-4.5来说,它在传统基准测试上展现出的改进,和GPT-3.5到GPT-4的跃升可以说十分类似。
除此之外,GPT-4.5还具备了很多新的能力。比如制作早期模型都无法完成的——ASCII Art。
值得一提的是,Mark Chen特别指出——GPT-4.5在开发过程中并没有特别困难。
「我们所有基础模型的开发都是实验性的。这通常意味着在某些节点停止,分析发生了什么,然后重新启动运行。这并非GPT-4.5特有的情况,而是OpenAI在开发GPT-4和o系列时都采用的方法。」

参考资料:
https://scale.com/leaderboard
https://x.com/GaryMarcus/status/1895299900952453362
https://x.com/jeremyphoward/status/1895279057614577828
https://the-decoder.com/gpt-4-5-is-proof-that-we-can-continue-the-Scaling-paradigm-says-openais-chief-research-officer/
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
责任编辑:韦子蓉 现货白银杠杆